
僕はSokki VoiceというGoogleの音声認識でWindowsの任意のアプリケーションに音声入力できる音声入力ソフトを公開しています。
そんな僕には以前から気になっていた音声認識APIがありますそれはローカルで動作するVoskという音声認識のAPIです。最近の音声認識はインターネット上で音声認識をするものが多いのですが、その際に気になるのが音声認識させた情報に関するプライバシーの問題です。ブログで公開するような情報であれば特に気にする必要はないかもしれませんが、守秘義務があるような機密情報をオンラインで音声認識する際には十分に注意が必要です。セキュリティについてしっかり対策しているとしても情報が絶対に漏洩しないとは言えません。そういった意味でローカルで音声認識できるというのはとても大きなメリットかと思います
そこで今回僕はオフラインで音声認識できるVoskを利用したWindows用のデスクトップアプリケーションを作っていろいろテストしてみました。ちなみにこの記事もVoskで音声認識して直接WordPressに音声入力しています(90パーセント程度は音声入力で書いています)。
「ItumoVoice」を公開しました(2023/8/16)
Voskを使用したWindows用の音声入力ソフト「ItumoVoice」を公開しました。
・ソフト価格:3000円(消費税・手数料込み)
・30日間の無料での試用期間あり
※30日間経過した後もこちらからソフトの購入を促すことはありません。不要になった場合はソフトを削除してください。
ItumoVoiceをダウンロードしてから音声入力するまでの手順はこちらで確認できます。
◯ItumoVoiceをダウンロードする方は下記のリンクからダウンロードすることができます。

※インターネットを介しての音声入力で差し支えない場合は、Sokki Voiceをおすすめします。
Voskとはどんな音声認識のAPI?
まずはVoskがどんな音声認識APIかその特徴を挙げると
- ローカルで音声認識ができる(音声データをインターネットに送信しない)
Voskのメリットは何といってもここが一番大きいと思います。オンラインの音声認識ではセキュリティー面で心配なので音声入力が使えなかったという方にはここが決定的なメリットになると思います。 - 音声認識のモデルは日本語の場合50MBの小さいモデルと1GBのモデルを選択することができる
- 50MBの軽量なモデルは音声アシスタントといった使い方ができそう。
- 1GBのモデルを使用すればブログなどの記事を書くことにも十分使える。
※1GBのモデルを使用する場合はアプリの消費メモリが多くなる(~1.6GB程度)
- クロスプラットフォームで使える音声認識APIなのでWindowsだけではなくMacやアンドロイドなどでも使用できる。
- 対応している言語も多い。20以上の言語と方言をサポート
- 開発に用いることができる言語も多い(Python、JavaScript/Nodejs、C♯など)
- 話者を識別することもできる
話者の声の特徴を表わす数値データ(配列)を音声認識結果とともに出力してくれる。声の特徴を表すデータを解析して話者を特定する処理はアプリケーション開発者の側で実装する必要がある。 - ハードルは高いが音声認識モデルを再構築することができる
※小さいモデルではもう少し簡単に動的に語彙を再構成できるようです。ただ僕が使い方をよく分かっていないだけかもしれませんが、C#だとできないのかもしれません(Voskには語彙を再構成するメソッドが無いです)。
Pythonの例ではKaldiを使用して語彙を再構成していますが、C#での使用例にKaldiの使い方が紹介されていないです。C#では今のところKaldiが使えないのかもしれません。
Voskはこのように非常に魅力的な音声認識のAPIになります。
そこで今回はC#でVoskを利用したWindows用のデスクトップアプリを作って色々試してみました。
今回テストした内容は以下の内容です。
- 音声からテキストへの変換精度
- リアルタイムで音声認識をする際のレスポンス
- 音声入力をするWindows用のデスクトップアプリとして使えるか
- この記事を実際にVoskの音声認識をブログを書くことができるか(この記事をVoskへの音声認識を使って実際に書いてみてテストする)
試した結果は、
上記の1、2、3に対しては良好な結果で十分に使えるというのが僕の結論です。
3番に関してはWindows用のデスクトップアプリとして作成できますが、そのアプリの導入がSokki Voiceに比べると少し面倒かなという感じです。
上記4に関しては、実際にこのブログはVosk(1GBのモデル)の音声認識を利用して、その認識結果をワードプレスに送る形で入力して作成しました。全てキーボードで入力するのに比べればはるかにスムーズにブログが書くことができると思います。
今回Voskを試した僕のPC環境
今回試したPC環境は、OSはWindows 11のHome Editionで搭載しているメモリーは8GBになります。詳細は下記の通りです。今回試したPC環境ではストレスなく音声入力することができました。
デバイス名 LAPTOP-3L4S4QJ4
プロセッサ Intel(R) Core(TM) i5-8265U CPU @ 1.60GHz 1.80 GHz
実装 RAM 8.00 GB (7.77 GB 使用可能)
システムの種類 64 ビット オペレーティング システム、x64 ベース プロセッサ
音声をテキストに変換する際の変換精度とレスポンス
Voskで日本語を音声認識する場合は50MBのモデルと1GBのモデルを選択することができます。
そこでまずはモデルのサイズによる違いを見ていきたいと思います。
1.1GBのモデル VS 50MBのモデル
テストは公平に行うために、モデルサイズ50MBで認識するアプリとモデルサイズ1GBで認識するアプリを同時に起動して同じタイミングで話して音声認識させてみました。
原文:
公平にテストするために同時にマイクに話して音声認識のテストをしています
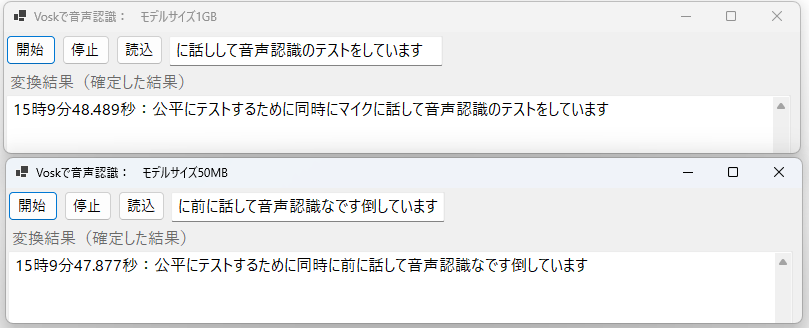
1GBのモデルの方は正確に音声認識してくれました。一方で50MBの方は僕の発音が不明瞭な部分があるのかもしれませんが僕の意図した内容とは結構違って認識されています。Voskの音声認識を使って文章を書くことを考えた場合は1GBのモデルを選択した方がよさそうです。
50MBの方は音声アシスタントとかそういった使用方法であれば使えるのかもしれませんが、記事作成とかには向かないのではないかなと思います。
また上のテスト結果の左の時刻は最終的な音声認識の結果が返ってきた時刻になります。
音声認識の結果が返ってくるまでの時間は大体0.5秒ぐらい50MBの方が早いことが多いです。
ただ0.5秒でこの変換精度の差であれば基本的には1GBのモデルを使用する方がいいのかなと思います。
次はGoogleの音声認識とVosk(モデルサイズ1GB)の音声認識で比較していきたいと思います。
2.Voskの音声認識(1GB) vs Googleの音声認識(Web Speech API)
ここまでこの記事をVoskの音声認識を使って書いてきて、Voskの音声認識も一般的な言葉を使った文書であれば十分に正確に音声認識できることがわかったので、次は固有名詞などあまり一般的ではない単語も含めて音声認識のテストをしていきたいと思います。
原文
今日の給食の献立はしょうゆご飯、けんちん汁、タレカツ、春雨サラダになります。
Voskで音声認識:
今日の給食の献立は醤油ご飯けんちん汁タレカツ春雨サラダになります
Googleの音声認識(Web Speech API):
今日の給食の献立は醤油ご飯けんちん汁タレカツ春雨サラダになります
この程度であればどちらも正確に音声入力できます。
次は新潟にある公園の名前を使って音声認識のテストをしてみます。
原文:
先週の日曜日は天気が良かったので、少し距離はありますが、上堰潟公園に行ってきました。
Voskで音声認識:
先週の日曜日は天気が良かったので少し距離はありますが噂キー型公園に行ってきました
Googleの音声認識(Web Speech API):
先週の日曜日は天気が良かったので少し距離はありますが上堰潟公園に行ってきました
テストで使用した公園の名前は全国的にはあまり有名ではないのですがGoogleの音声認識の方は正確に音声認識してくれました。一方でVoskの音声認識の方は公園の名前は正確に認識してくれませんでした(それ以外は正確に認識してくれました)。
次は適当にいくつかテーマパークや公園の名前を音声認識させてテストしてみたいと思います。
○テーマパークや公園の名前でVosk(1GB)とGoogleの音声認識を比較
| 名称 | Voskの音声認識 | Googleの音声認識 |
| 東京ディズニーランド | 東京ディズニーランド | 東京ディズニーランド |
| ユニバーサルスタジオジャパン | ユニバーサルスタジオジャパン | ユニバーサルスタジオジャパン |
| 妙高サンシャインランド | 妙高サンシャインランド | 妙高サンシャインランド |
| サントピアワールド | サントピアワールド | サントピアワールド |
| 昭和記念公園 | 昭和記念公園 | 昭和記念公園 |
| 葛西臨海公園 | 葛西臨海公園 | 葛西臨海公園 |
| 上信越高原国立公園 | 上信越高原国立公園 | 上信越高原国立公園 |
| 県立紫雲寺記念公園 | 県立紫雲寺記念公園 | 県立紫雲寺記念公園 |
| 秋葉公園 | 秋は公園 | 秋葉公園 |
| 西川ふれあい公園 | 西川ふれあい公園 | 西川ふれあい公園 |
Googleの音声認識の方はすべて正確に音声認識してくれました。一方でVoskの音声認識の方は一つ間違えましたがそれ以外は問題なく音声認識できました。
次はアルファベットを含む言葉や数字を含む言葉で試してみたいと思います。
○アルファベットや数字でVosk (1GB)とGoogleの音声認識を比較
| テストする内容 | Voskの音声認識 | Googleの音声認識 |
| Amazon | アマゾン | Amazon |
| Windows | ウインドウズ | Windows |
| Google | ||
| Microsoft | Microsoft | Microsoft |
| ABC | ABC | ABC |
| XYZ | XYZ | XYZ |
| 10円 | 十円 | 10円 |
| 20円 | 二十円 | 20円 |
| 100円 | 百円 | 100円 |
| 110円 | 百十円 | 110円 |
| 10 | 中 | 10 |
| 20 | 二十 | 20 |
| 40 | 四十 | 40 |
| 100 | 百 | 100 |
| 110 | 百獣 | 110 |
Googleの音声認識の方は僕の期待した通りにテキストへ変換してくれます。
一方でVoskの音声認識の方は、
- アルファベットに変換してほしいところがカタカナに変換される
- アルファベットは全角文字のアルファベットになる
- 数字はアラビア数字じゃなく漢数字になることが多い
- 数字の音声認識はちょっと苦手
※ItumoVoiceでは全角のアルファベットを半角のアルファベットに変換したり、必要に応じて漢数字をアラビア数字に変換するなどして音声入力するようにしています。
アルファベットに変換してほしいところがカタカナに変換されたり、アルファベットはアルファベットでも全角文字になっていたりしていますが、この辺はアプリケーション側で「認識した文字」を「実際に変換したい文字」に置き換える補正処理や、全角文字を半角文字に置き換える処理を実装すれば問題ありません。
ただエクセルなどの一覧表にどんどん数値を音声で入力していくというような使い方には向いてなさそうです。
続いてGoogleの音声認識(Web Speech API)とVoskの音声認識のレスポンスの違いを比べてみたいと思います。こちらは同時にマイクに話して音声認識の最終結果が返ってくる時刻を比較しました。
○同時にマイクに話して音声認識結果が確定した時刻の比較
| テストに利用した文書(言葉) | Vosk (1GB) | |
| 今日は手作りのアイスクリームを子供と一緒に作って食べてみました | 15時21分30.183秒 | 15時21分29.122秒 |
| 子供は手作りのレベルではないととても喜んでいました | 15時23分59.93秒 | 15時23分58.79秒 |
| りんご | 15時25分48.974秒 | 15時25分48.397秒 |
| みかん | 15時26分41.268秒 | 15時26分40.274秒 |
Googleの音声認識とVoskの音声認識を比較すると約1秒Googleの方が最終認識結果が返ってくるのが早いです。Voskの音声認識の方はGoogleのそれと比較するとちょっと遅いけど十分に実用的なレベルだと言えると思います。
ここまでの音声認識の精度の確認についてはヘッドセットのマイクを使って確認してきました。
続いてPCに初めから付いている内蔵マイクだとどうなるか確認してみました。

○Voskの音声認識 (1GB) vs Googleの音声認識 (内蔵マイクを使った場合、静かな場所)
まずは静かな環境でPCに内蔵しているマイクを使って比較してみました。
結果はどちらも正確に音声認識をして差は出ませんでした。
原文:
公平にテストするために同時にマイクに話して音声認識のテストをしています
Vosk:
公平にテストするために同時にマイクに話して音声認識のテストをしています
Google:
公平にテストするために同時にマイクに話して 音声認識のテストをしています
次にノイズの多い環境でテストしてみました。
○Voskの音声認識(1GB) vs Googleの音声認識 (内蔵マイクを使った場合、ノイズが多い環境)
次にVoskの音声認識とGoogleの音声認識で差を出す為にあえて意地悪な環境(リビングのガチャガチャしている環境)でPCの内蔵マイクを使用して音声認識を行ないました。
原文:
公平にテストするために同時にマイクに話して音声認識のテストをしています
Vosk(1回目):
ホームテストするために同時にマイクに話で音声認識のかをしています
Vosk(2回目):
公平にテストするために童話風に舞いに話で音声認識のテストをしています
Google(1回目):
縫製にテストするために同時にマイクに話して音声認識のテストをしています
Google(2回目):
公平にテストするために同時にマイクに話して音声認識のテストをしています
静かな環境ではPCの内蔵マイクを使用した場合もVoskとGoogle共にどちらも正確に音声認識できたのですが、ノイズの多い環境で比較するとGoogleの音声認識の方が認識率が高かくなっていました。
○Voskのテキストに変換する際の特徴
- 音声認識の変換精度は高い(1GBを使用した場合)
- 数字を漢数字で認識することが多い
例えば「二千二十三年」という風に漢数字で認識されることが多いです - アルファベットは全角文字で認識される
数字を漢数字で認識したりアルファベットが全角文字で認識されるという点に関してはアプリケーションを開発する側の人でアラビア数字に変換したり全角文字を半角文字に変換することはそんなに難しくないのであまり大きな問題ではないとは思います。
※ItumoVoiceでは全角のアルファベットを半角のアルファベットに変換したり、必要に応じて漢数字をアラビア数字に変換するなどして音声入力するようにしています。
次にVoskを使ったデスクトップアプリをC#で作ってみて僕が思ったメリットとデメリットについてまとめてみたいと思います。
今回試して感じたVoskのいいところ
- ローカルの環境で音声認識できるためセキュリティ面で安全、情報漏洩のリスクがない
やっぱり何といってもVoskのいいところはここに尽きると思います。 - 1GBのモデルを利用すれば十分な音声認識の精度で音声で文章の作成ができる
今回のこの記事は約90%はVoskの音声入力を使って書きましたがストレスなく音声入力することができました。 - マイクで話した内容を音声認識する以外にも音声ファイルをステレオで再生せずともテキストに変換することができる
- 議事録を作成するような使い方をする場合は、話した人を識別するためのモデルも利用できる
話した人の声の特徴が数値の配列として返ってきます。事前に識別したい人の声を表わす数値配列を登録しておいて、音声認識した際にすでに登録されている人の中で1番近い人を話者とするような処理を実装します。
僕が家族の声を登録して試した感じでは結構正確に誰が話したかを区別してくれました。ただし姉弟で声が似てるようなケースでは間違えるというケースもそれなりにありましたが、ここについては親の僕が聞いても顔を見ないとどっちが話してるかわからなくなるような時がある感じなので、ここはしょうがないかなという気がします。
僕の感じたVoskのあともう一つというところ
- VoskをWindowsのデスクトップアプリとして使う場合は、実行環境として.NET6もしくは.NET5の実行環境が必要。
.NET6や.NET5はMicrosoftが公式に公開しているのでダウンロードとインストールすること自体は簡単ですが、僕が知っているWindowsの大抵のデスクトップアプリは対象のアプリだけインストールすれば使えるものが多いのでちょっと面倒くさいなと感じてしまいます。
.NET6は一度インストールすればいいので、今後.NET6が必要なアプリケーションが増えてくれば特に気にならなくなるかもしれませんが、僕としてはやっぱり初めからWindowsにインストールされている.NETFrameworkでもVoskが使用できるようになることを期待しています。
※ .NET6や.NET5は自分でMicrosoftのサポート期間を把握して必要に応じて更新する必要があります。 - 十分な認識精度を獲得しようとするとアプリケーションのサイズが1GB以上になる
十分な音声認識の精度を獲得しようとすると50MBのモデルではなく1GB(解凍すると1.5GB程度)のモデルが必要になるため、かなりサイズの大きいアプリになってしまいます。
例えばベクターから公開しようとした場合、公開するファイルのサイズはCD-ROM1枚に収まる程度(~700MB)にしてほしいとあるのですが、これを大きく超えています。なのでこのアプリケーションを公開しようとする時は1GBのモデルはベクターからは公開できないと思います。
※先日僕のソフトの開発環境であるVisual StudioをVisual Studio 2019からVisual Studio 2022に変更しましたが、その際にVisual Studio 2019をアンインストールしたところ容量が21.3GB増えました。なのでそれに比べれば全然小さいサイズなのかなと思います。 - 1GBのモデルを使用した場合アプリの消費メモリが~1.6GB程度になる
僕のPCの場合はアプリを起動した直後は使用するメモリーが1.6GB程度になることが多いです。しばらく使っていると500MB程度まで下がることもありますが、アプリの消費メモリはかなり多くなってしまいます。
1GBのモデルを使う場合は最低でもPCに8GBのメモリが搭載されてる必要があると思います。 - ローカルで音声認識するため使用するPCによってパフォーマンスが違ってくる可能性がある
今回テストで利用した僕のPCはWindows 11です。特別スペックが高いパソコンではありませんが、比較的スペックの高いパソコンと言えると思います。もっとスペックの低いPCでどのように動作するかについてはまだテストしていません。 - 音声認識の結果が返ってくるまでの間がちょっと気になる(レスポンスがちょっと遅い)
音声認識をテキストの入力に利用するという使い方の場合は十分に実用的なレスポンスだとは思います。ただショートカットキーの操作を音声で行なうための音声コマンドとして利用するにはレスポンスが少し遅いと思います。 - エクセルなどの表に数値をどんどん入力していくというような使い方には向いていない
数値の音声認識についてはちょっと苦手で、レスポンスもちょっと遅めなので表に数値をどんどん入力していくというような使い方にはあまり向いていないと思います。
まとめ
Voskは守秘義務の観点からオンラインの音声認識を使うことができない人にはとても魅力的なAPIです。
一方でオンラインで音声認識をすることが特に問題ない人にとっては、Googleの音声認識を利用したSokki Voiceの方が「音声認識の精度」、「レスポンス」、「導入の手軽さ」という点で優れているのでSokki Voiceの方がおすすめです。
Sokki VoiceはWindowsの任意のアプリに音声入力できて、音声コマンドで他のアプリを起動したり、音声でショートカットキーの操作などのキーボード操作も可能になります。
興味のある方はぜひ一度使ってみてください。
※ItumoVoiceとSokki Voiceはどちらも筆者が開発した音声入力ソフトになります。
Sokki Voiceは公開開始より2年以上にわたり改良を重ねて便利な機能がたくさんあります。
後から公開したItumoVoiceについてはSokki Voiceの主な機能を盛り込んだ形になっています。
これからC#でVoskを利用したアプリを作成しようと思っている方へ
僕がC♯で今回のVoskを利用したアプリを作成する上でのポイントについて簡単に書いておきます。
Voskの利用方法については下記の公式のウェブサイトに説明してあります。C#での利用方法も記載してあります。

C#でVoskを利用する際のポイント
- Voskは.NETFrameworkでは利用できない為.NET5や.NET6を利用する必要がある(今のところ)。
- Visual Studioを使ってる場合はNuGetを使用してVoskを簡単にインストールすることができます。
- VoskのAPIの使用方法についてはデモ用のソースコードを参照しました。
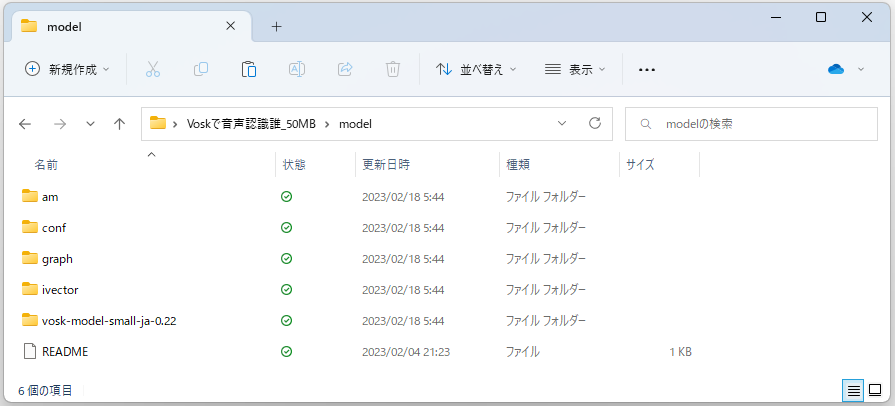
- 音声認識モデルをダウンロードして、エグゼファイルと同じ場所に「model」フォルダを作成して
ダウンロードしたZipファイルを解凍してその中身をコピーする(下図を参照)。
※モデルのインスタンスを作成する時にModel model = new Model(“model”);とした場合。 - Voskの音声認識に音声データを渡す際には16000hz、1チャンネル(モノラル)にする必要がある。
- 音声認識の精度を良くするためには話し終わったタイミングで最終結果を取得するように調整する必要があります。僕が今回ためした方法は、
- マイクが音声を検出したタイミングを取得するために、PartialResult()を利用
話し始めた直後に最終結果を取得しないようにするために、僕はPartialResult()を利用してマイクが音声した検出した時間を取得してそこから0.7秒間は FinalResult()は使用しないようにしました。 - 音声認識が固まらないようにするために、Result()を利用
- 確定した結果を入力する際には、FinalResult()を利用
- ノイズは音声として検出することがあるので、ノイズと思われる変換結果に対しては前処理で削除しました。
- マイクが音声を検出したタイミングを取得するために、PartialResult()を利用

コメント
私は、この程、「商用・非商用問わず無料 のVOICEVOX」という音声合成ソフトがある事を
知り、自分のWindows10 i5マシンにインストールしてみたいと思いWebの情報を探して
ました。そこで、そのソフトと「VOSK」を利用して、今、話題となっている「ChatGPT」の
入力ができれば、と考えている方がいらして、偉く共感したものの、自分がC/C++しか
扱えず、C#やJAVA等の言語が扱えないので、この「VOSK」の評価やアプリ作りが出来ま
せん。そこで、もっと簡単に「Vosk」が扱える方法がないかと、ご経験のある御貴殿に
お聞きしたくメールしてみました。
予てから、私は、マイコンを使った回路設計やファームを設計しているのですが、デバイス
や操作等のアプリケーション・ノートの解読には、その多さに疲弊して参りました。
そこで、昨今、世間では、「ChatGPT」を使って、ソースコードを書かせたり、エラー処理
の問い合わせをしたりしているという事を知り、自分も始めてますが、その問い合わせの
入力が、面倒でなりません。
そこで、思い付いたのが、『音声認識』という訳です。
いろいろな方のサイトを拝見しているうちに、御貴殿のサイトに惹かれ、熟読したという
訳です。
最近、自分は、Cもしくは、C++のソースコードを「ChatGPT」に書かせてみたいとい
うつまらない願望に駆られ、現在、わたしが考えていることは、
①「Vosk」で音声入力させて、②「ChatGPT」に反応させ、③「Viocevox」で、女性アナウ
ンサー的にしゃべらせて会話をして、④「Code Editor」でその結果を文字にして残したい
という、アプリとアプリを繋いでくれるようなソフトウエアを探してます。
そのためにも「Vosk」の性能と簡単利用方の詳細を探してました。言語の相違があり、自分
に100%理解できるか判りませんが、もう少し細かく教えて頂けると幸いです。 敬具
from 上州トマト
田口様
コメントありがとうございます。
>現在、わたしが考えていることは、
>①「Vosk」で音声入力させて、②「ChatGPT」に反応させ、③「Viocevox」で、女性アナウ
>ンサー的にしゃべらせて会話をして、④「Code Editor」でその結果を文字にして残したい
>という、アプリとアプリを繋いでくれるようなソフトウエアを探してます。
アプリをつないでくれるようなソフトを探してるということであれば、
僕が現在公開しているSokki Voice(話してパソコン入力 via the Web)で可能かと思います。
Sokki Voiceは任意のアプリケーションに入力できるので目的が達成できると思います。
Sokki Voiceのダウンロードはこちらから
それとも、自分でVoskの音声認識アプリを作成することを目的にしてるのでしょうか?
C#を使ったことがないということだと結構先が長そうな気がします。
まずはVisual Studio 2022を使ってVoskのデモンストレーション用のソースコードを動かすところから初めて見るのがいいと思います。
デモンストレーション用のソースコードは音声ファイルをテキストに変換するプログラムになっています。
デモンストレーション用のソースコードを動かすことができるようになったら、今度はマイクからのストリーミングをVoskに渡すようにしたらいいのではないかと思います。
ちなみにマイクから音声のストリーミングを取得するのにはNaudioというライブラリを使いました。
こちらもボスクと同様にNuGetからインストールできます。
あと、どこでつまづいてるかがわかると説明がしやすいです。
Your content offers something for everyone; it’s beneficial for both seasoned and newbie readers.
VOSKの日本語modelへの単語追加の方法が2023年10月にようやく分かりました。Nickolay Shmyrevさんには連絡済みですがまだ公開されてません。そちらで公開してもらうことは出来ますか?
大久保様
C#でVOSKを使用した場合も日本語modelへの単語の追加できるんでしょうか?
音声認識モデルに単追を加しているサンプルのソースコードはKaldiを使用していたので、
kaldiなら出来るのかなと思いC#でkaldiを使おうとしたけど使い方が分からなかったんです。
もしC#でも出来るのであれば是非とも教えていただきたいです。
返事が大幅に遅れて申し訳ありません。
日本語版の場合、VOSKでの単語追加の方法が
https://alphacephei.com/vosk/lm
といくつか異なります。
2024年12月から以下が更新され、カタカナ単語だけでなく漢字なども含む文字も追加出来るようになりました。
日本語の場合、
https://alphacephei.com/test-other/ueda-shimotanabe/vosk-model-ja-0.22-compile.tar.gz
から、ダウンロードします。
>C#でVOSKを使用した場合
何をやりたいか?が正確に理解出来てなあかもしれない返事かもしれません。「C# 外部プログラム」で検索してみてください。
大久保様
色々丁寧に教えていただきありがとうございます。
最近私が色々忙しくて中々Voskの音声認識エンジンの中まで手を出せていないだけです。
親切に教えてくださりありがとうございます。
「model」フォルダの中身をそっくり日本語用に入れ替えるだけなので、C#から動作させているVOSKでも行けるかもしれません。